Publications
publications by categories in reversed chronological order.
2026
-
 Membership Inference Attacks on Finetuned Diffusion Language ModelsYuetian Chen, Kaiyuan Zhang, Yuntao Du, and 5 more authors14th International Conference on Learning Representations, 2026
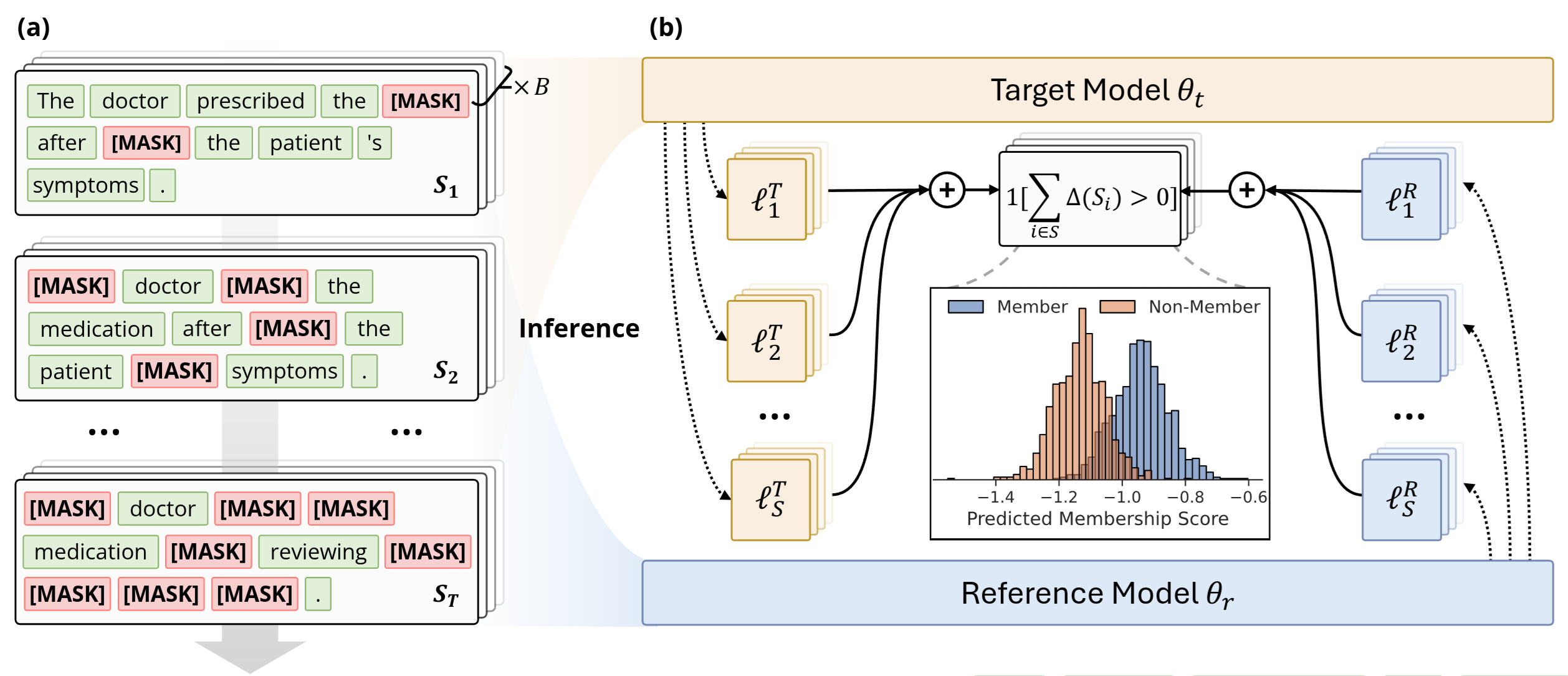
Membership Inference Attacks on Finetuned Diffusion Language ModelsYuetian Chen, Kaiyuan Zhang, Yuntao Du, and 5 more authors14th International Conference on Learning Representations, 2026Diffusion Language Models (DLMs) represent a promising alternative to autoregressive language models, using bidirectional masked token prediction. Yet their susceptibility to privacy leakage via Membership Inference Attacks (MIA) remains critically underexplored. This paper presents the first systematic investigation of MIA vulnerabilities in DLMs. Unlike the autoregressive models’ single fixed prediction pattern, DLMs’ multiple maskable configurations exponentially increase attack opportunities. This ability to probe many independent masks dramatically improves detection chances. To exploit this, we introduce SAMA (Subset-Aggregated Membership Attack), which addresses the sparse signal challenge through robust aggregation. SAMA samples masked subsets across progressive densities and applies sign-based statistics that remain effective despite heavy-tailed noise. Through inverse-weighted aggregation prioritizing sparse masks’ cleaner signals, SAMA transforms sparse memorization detection into a robust voting mechanism. Experiments on nine datasets show SAMA achieves 30% relative AUC improvement over the best baseline, with up to 8x improvement at low false positive rates. These findings reveal significant, previously unknown vulnerabilities in DLMs, necessitating the development of tailored privacy defenses.
-
 Window-based Membership Inference Attacks Against Fine-tuned Large Language ModelsYuetian Chen, Yuntao Du, Kaiyuan Zhang, and 4 more authors35th USENIX Security Symposium, 2026
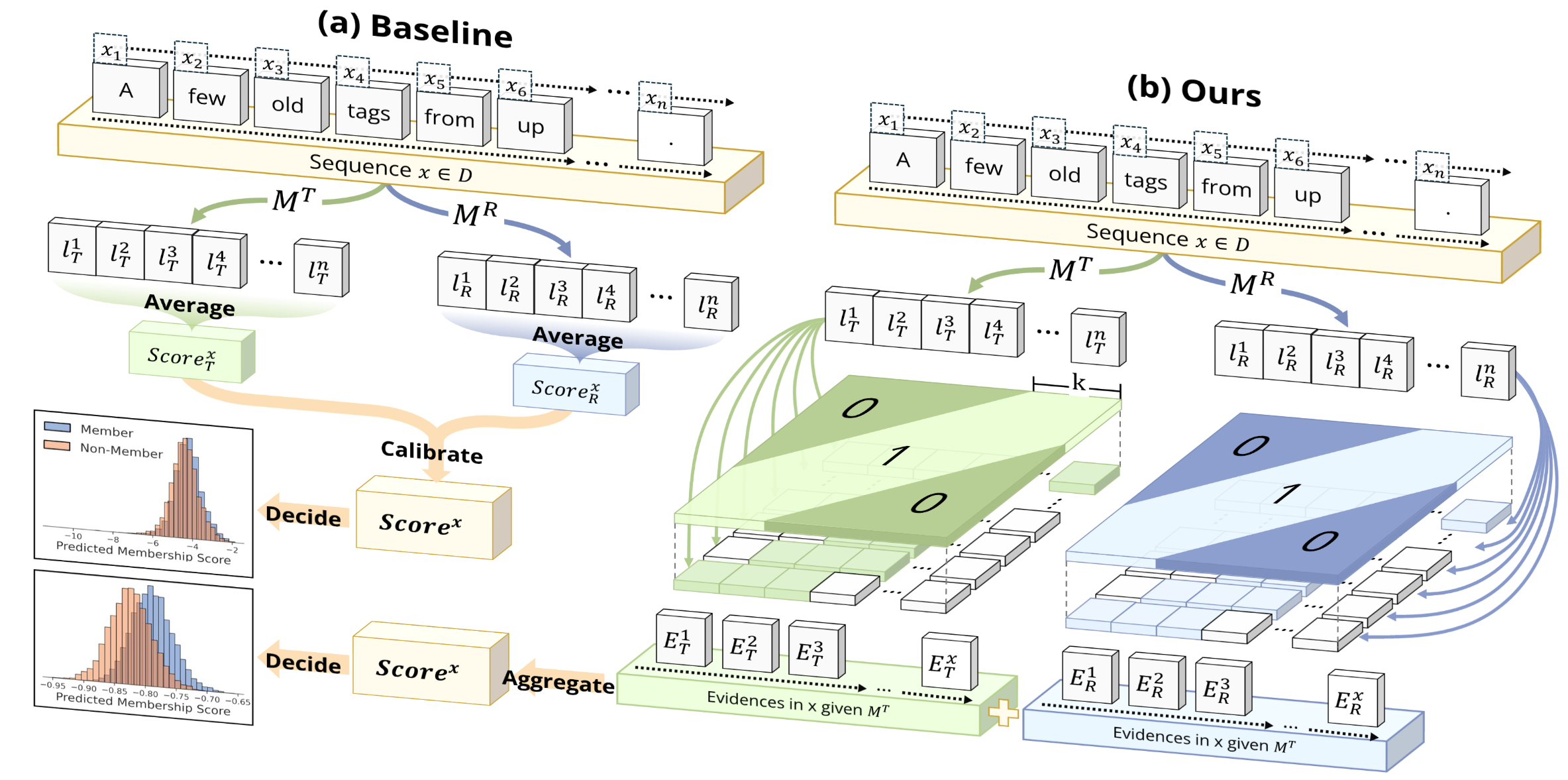
Window-based Membership Inference Attacks Against Fine-tuned Large Language ModelsYuetian Chen, Yuntao Du, Kaiyuan Zhang, and 4 more authors35th USENIX Security Symposium, 2026Most membership inference attacks (MIAs) against Large Language Models (LLMs) rely on global signals, like average loss, to identify training data. This approach, however, dilutes the subtle, localized signals of memorization, reducing attack effectiveness. We challenge this global-averaging paradigm, positing that membership signals are more pronounced within localized contexts. We introduce WBC (Window-Based Comparison), which exploits this insight through a sliding window approach with sign-based aggregation. Our method slides windows of varying sizes across text sequences, with each window casting a binary vote on membership based on loss comparisons between target and reference models. By ensembling votes across geometrically spaced window sizes, we capture memorization patterns from token-level artifacts to phrase-level structures. Extensive experiments across eleven datasets demonstrate that WBC substantially outperforms established baselines, achieving higher AUC scores and 2-3 times improvements in detection rates at low false positive thresholds. Our findings reveal that aggregating localized evidence is fundamentally more effective than global averaging, exposing critical privacy vulnerabilities in fine-tuned LLMs.
-
 Imitative Membership Inference AttackYuntao Du, Yuetian Chen, Hanshen Xiao, and 2 more authors35th USENIX Security Symposium, 2026
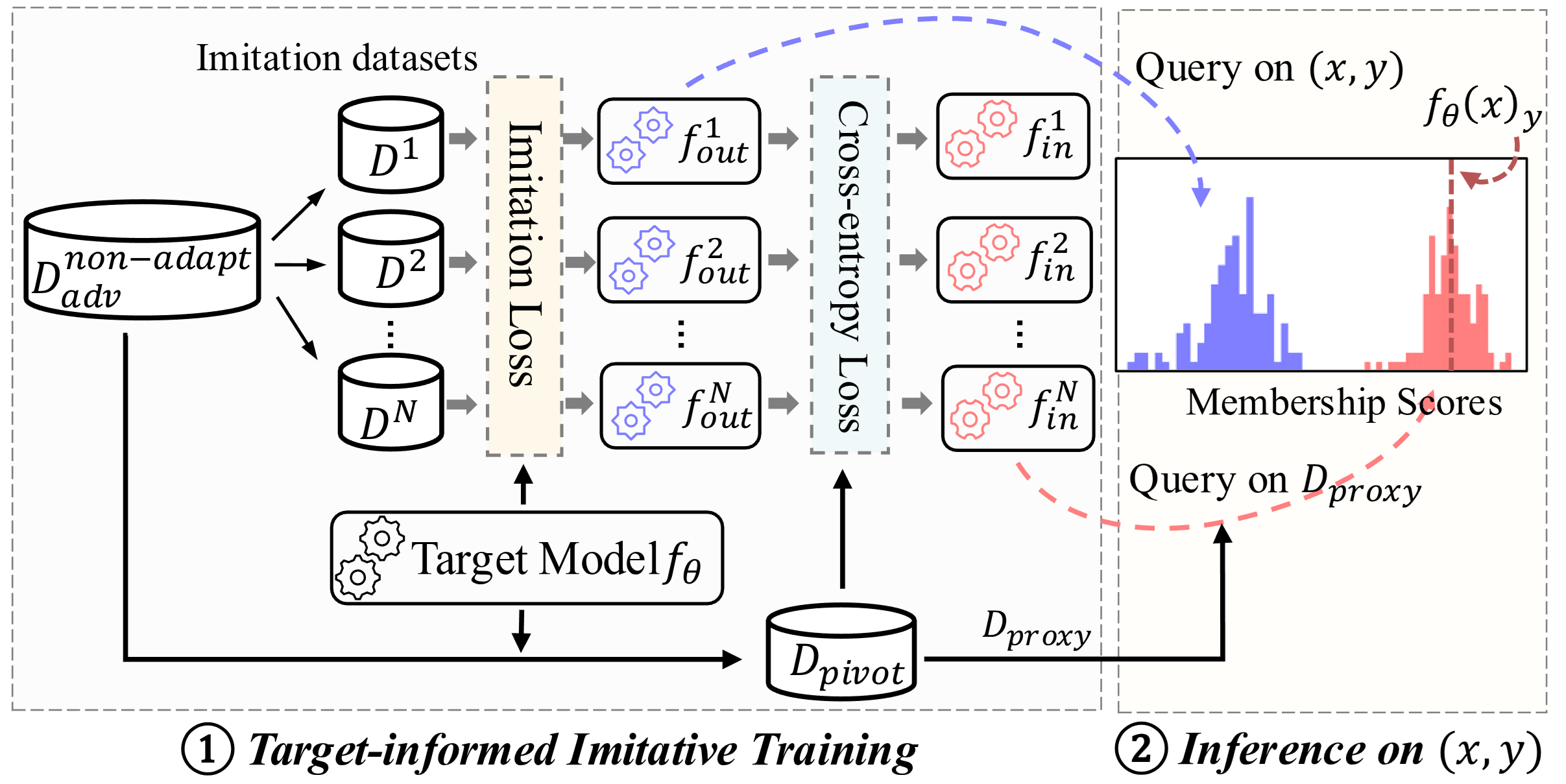
Imitative Membership Inference AttackYuntao Du, Yuetian Chen, Hanshen Xiao, and 2 more authors35th USENIX Security Symposium, 2026A Membership Inference Attack (MIA) assesses how much a target machine learning model reveals about its training data by determining whether specific query instances were part of the training set. State-of-the-art MIAs rely on training hundreds of shadow models that are independent of the target model, leading to significant computational overhead. In this paper, we introduce Imitative Membership Inference Attack (IMIA), which employs a novel imitative training technique to strategically construct a small number of target-informed imitative models that closely replicate the target model’s behavior for inference. Extensive experimental results demonstrate that IMIA substantially outperforms existing MIAs in various attack settings while only requiring less than 5% of the computational cost of state-of-the-art approaches.
-
 Cascading and Proxy Membership Inference AttackYuntao Du, Jiacheng Li, Yuetian Chen, and 5 more authorsIn Network and Distributed System Security Symposium (NDSS), 2026
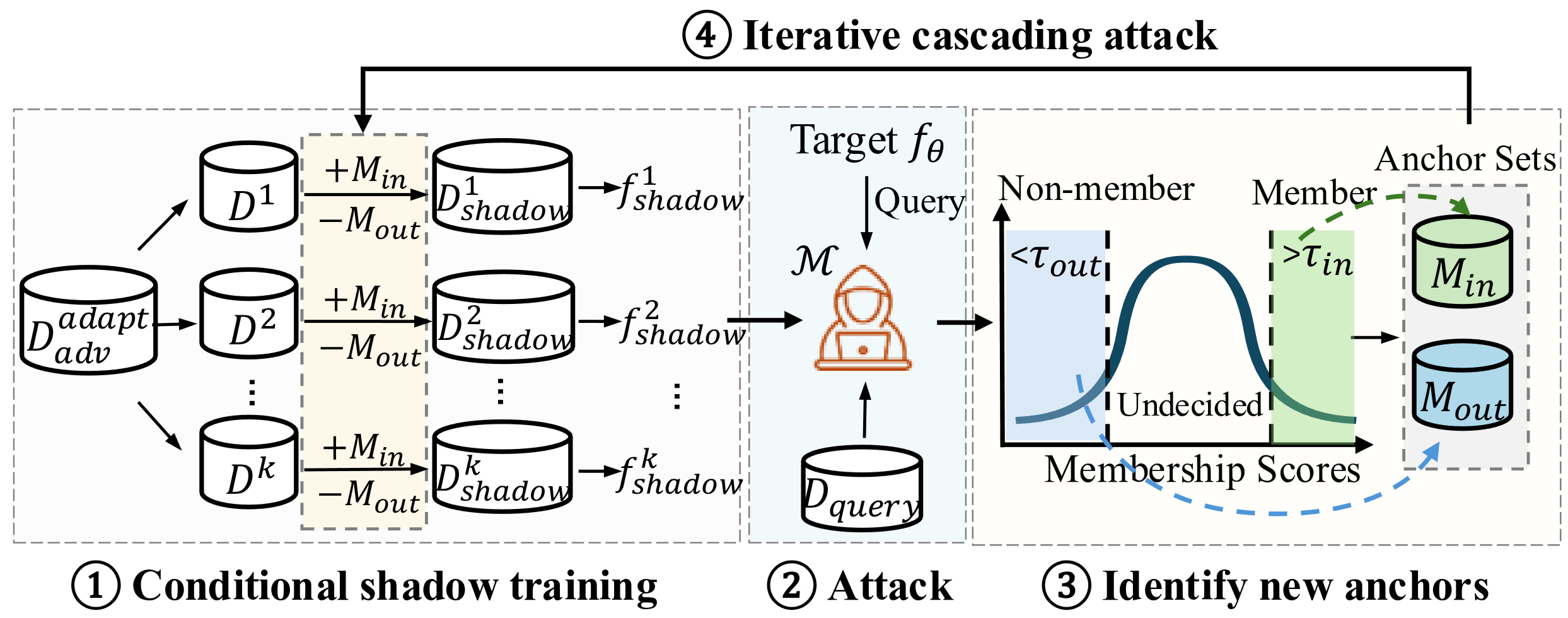
Cascading and Proxy Membership Inference AttackYuntao Du, Jiacheng Li, Yuetian Chen, and 5 more authorsIn Network and Distributed System Security Symposium (NDSS), 2026A Membership Inference Attack (MIA) assesses how much a trained machine learning model reveals about its training data by determining whether specific query instances were included in the dataset. We classify existing MIAs into adaptive or non-adaptive, depending on whether the adversary is allowed to train shadow models on membership queries. In the adaptive setting, where the adversary can train shadow models after accessing query instances, we highlight the importance of exploiting membership dependencies between instances and propose an attack-agnostic framework called Cascading Membership Inference Attack (CMIA), which incorporates membership dependencies via conditional shadow training to boost membership inference performance. In the non-adaptive setting, where the adversary is restricted to training shadow models before obtaining membership queries, we introduce Proxy Membership Inference Attack (PMIA). PMIA employs a proxy selection strategy that identifies samples with similar behaviors to the query instance and uses their behaviors in shadow models to perform a membership posterior odds test for membership inference. We provide theoretical analyses for both attacks, and extensive experimental results demonstrate that CMIA and PMIA substantially outperform existing MIAs in both settings, particularly in the low false-positive regime, which is crucial for evaluating privacy risks.
2025
-
 SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference AttacksKaiyuan Zhang, Siyuan Cheng, Hanxi Guo, and 8 more authors34th USENIX Security Symposium, 2025
SOFT: Selective Data Obfuscation for Protecting LLM Fine-tuning against Membership Inference AttacksKaiyuan Zhang, Siyuan Cheng, Hanxi Guo, and 8 more authors34th USENIX Security Symposium, 2025Large language models (LLMs) have achieved remarkable success and are widely adopted for diverse applications. However, fine-tuning these models often involves private or sensitive information, raising critical privacy concerns. In this work, we conduct the first comprehensive study evaluating the vulnerability of fine-tuned LLMs to membership inference attacks (MIAs). Our empirical analysis demonstrates that MIAs exploit the loss reduction during fine-tuning, making them highly effective in revealing membership information. These findings motivate the development of our defense. We propose SOFT (\textbfSelective data \textbfObfuscation in LLM \textbfFine-\textbfTuning), a novel defense technique that mitigates privacy leakage by leveraging influential data selection with an adjustable parameter to balance utility preservation and privacy protection. Our extensive experiments span six diverse domains and multiple LLM architectures and scales. Results show that SOFT effectively reduces privacy risks while maintaining competitive model performance, offering a practical and scalable solution to safeguard sensitive information in fine-tuned LLMs.
-
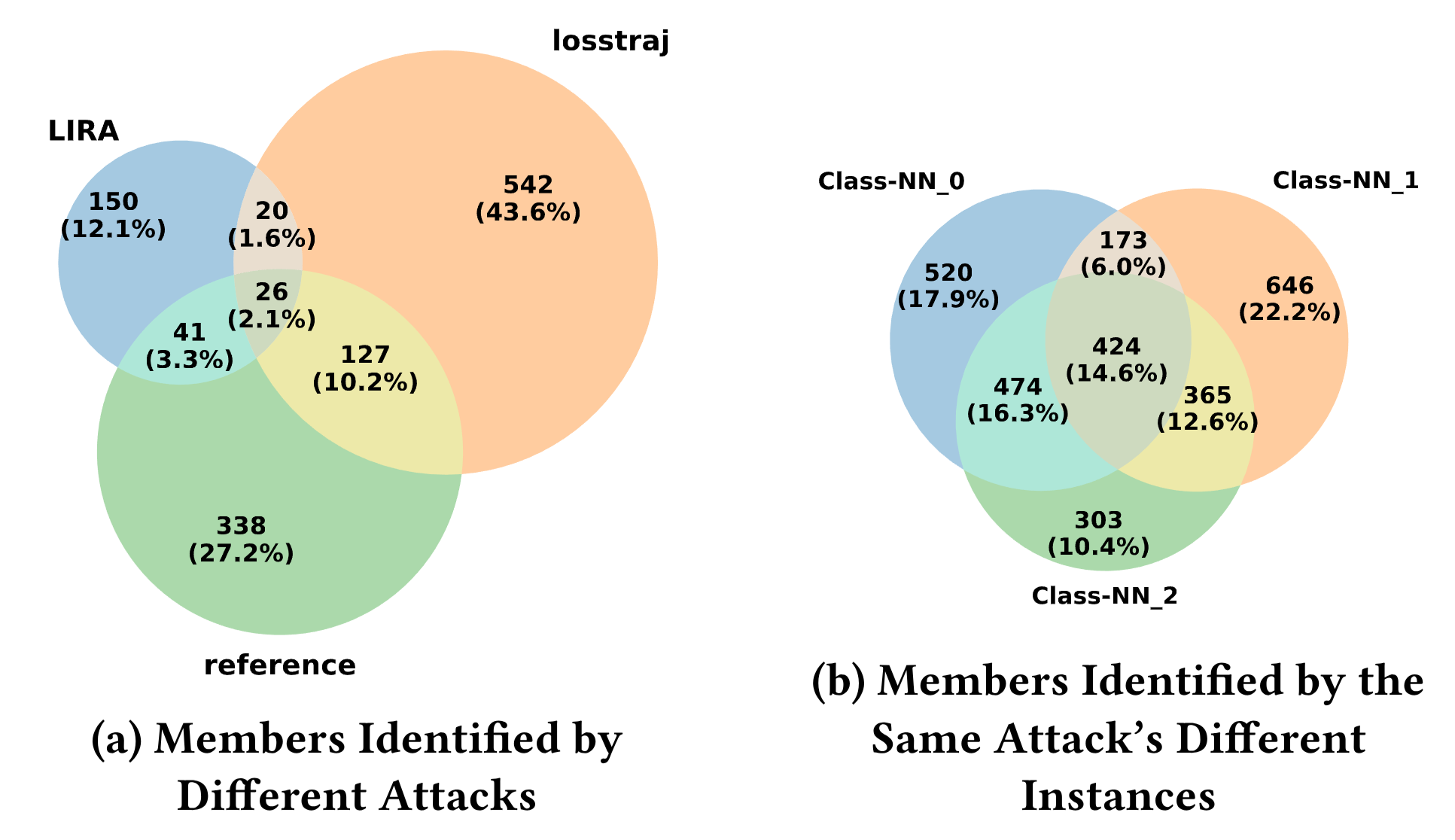 Membership Inference Attacks as Privacy Tools: Reliability, Disparity and EnsembleZhiqi Wang, Chengyu Zhang, Yuetian Chen, and 3 more authorsACM Conference on Computer and Communications Security, 2025
Membership Inference Attacks as Privacy Tools: Reliability, Disparity and EnsembleZhiqi Wang, Chengyu Zhang, Yuetian Chen, and 3 more authorsACM Conference on Computer and Communications Security, 2025Membership inference attacks (MIAs) pose a significant threat to the privacy of machine learning models and are widely used as tools for privacy assessment, auditing, and machine unlearning. While prior MIA research has primarily focused on performance metrics such as AUC, accuracy, and TPR@low FPR - either by developing new methods to enhance these metrics or using them to evaluate privacy solutions - we found that it overlooks the disparities among different attacks. These disparities, both between distinct attack methods and between multiple instantiations of the same method, have crucial implications for the reliability and completeness of MIAs as privacy evaluation tools. In this paper, we systematically investigate these disparities through a novel framework based on coverage and stability analysis. Extensive experiments reveal significant disparities in MIAs, their potential causes, and their broader implications for privacy evaluation. To address these challenges, we propose an ensemble framework with three distinct strategies to harness the strengths of state-of-the-art MIAs while accounting for their disparities. This framework not only enables the construction of more powerful attacks but also provides a more robust and comprehensive methodology for privacy evaluation.
-
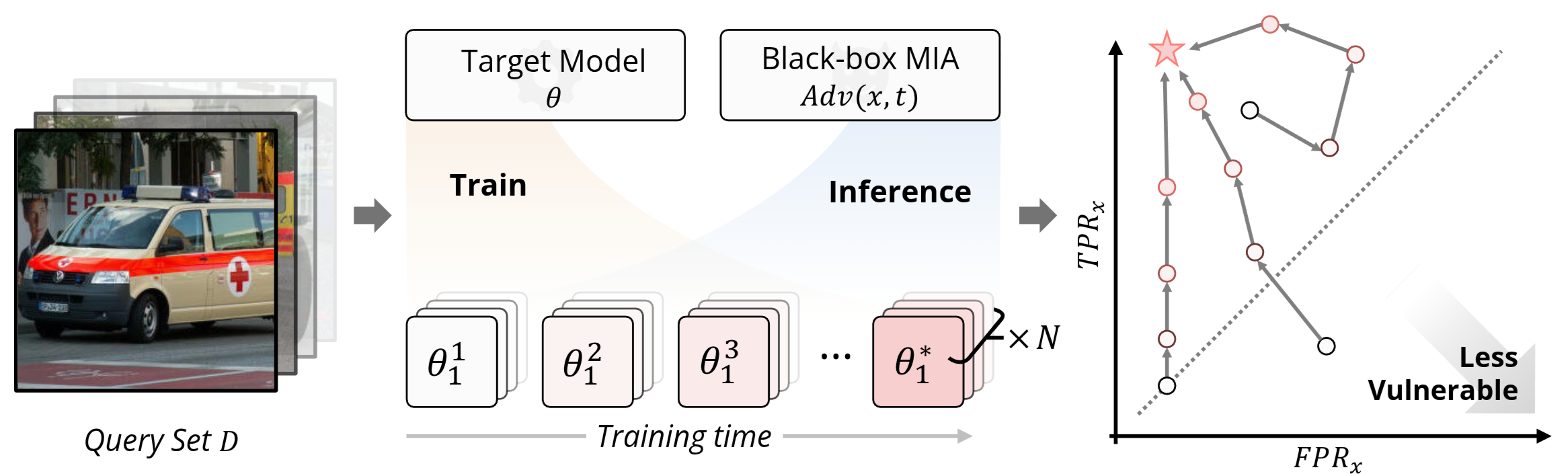 Evaluating the Dynamics of Membership Privacy in Deep LearningYuetian Chen, Zhiqi Wang, Nathalie Baracaldo, and 2 more authorsarXiv preprint arXiv:2507.23291, 2025
Evaluating the Dynamics of Membership Privacy in Deep LearningYuetian Chen, Zhiqi Wang, Nathalie Baracaldo, and 2 more authorsarXiv preprint arXiv:2507.23291, 2025Membership inference attacks (MIAs) pose a critical threat to the privacy of training data in deep learning. Despite significant progress in attack methodologies, our understanding of when and how models encode membership information during training remains limited. This paper presents a dynamic analytical framework for dissecting and quantifying privacy leakage dynamics at the individual sample level. By tracking per-sample vulnerabilities on an FPR-TPR plane throughout training, our framework systematically measures how factors such as dataset complexity, model architecture, and optimizer choice influence the rate and severity at which samples become vulnerable. Crucially, we discover a robust correlation between a sample’s intrinsic learning difficulty, and find that the privacy risk of samples highly vulnerable in the final trained model is largely determined early during training. Our results thus provide a deeper understanding of how privacy risks dynamically emerge during training, laying the groundwork for proactive, privacy-aware model training strategies.
2024
-
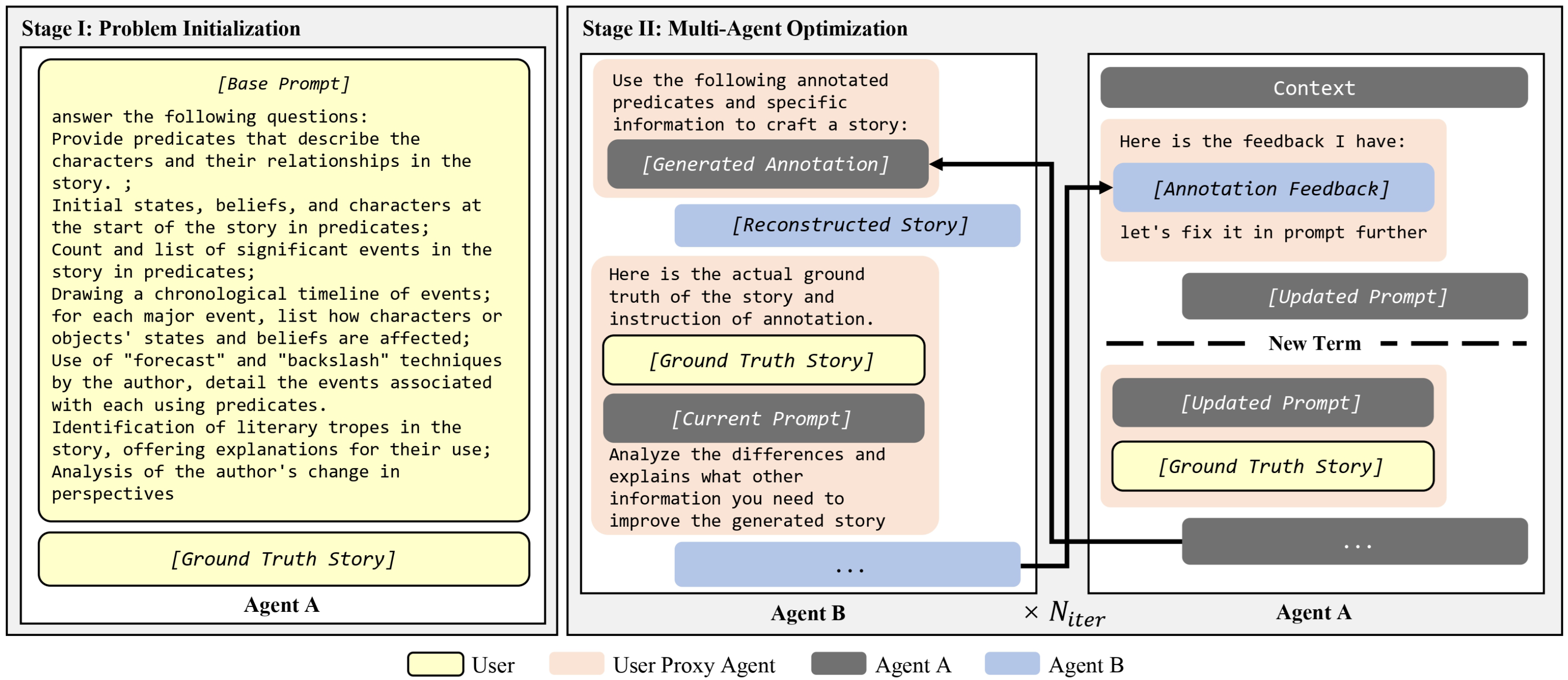 Reflections & Resonance: Two-Agent Partnership for Advancing LLM-based Story AnnotationYuetian Chen and Mei SiIn Joint International Conference on Computational Linguistics, Language Resources and Evaluation, 2024
Reflections & Resonance: Two-Agent Partnership for Advancing LLM-based Story AnnotationYuetian Chen and Mei SiIn Joint International Conference on Computational Linguistics, Language Resources and Evaluation, 2024We introduce a novel multi-agent system for automating story annotation through the generation of tailored prompts for a large language model (LLM). This system utilizes two agents: Agent A is responsible for generating prompts that identify the key information necessary for reconstructing the story, while Agent B reconstructs the story from these annotations and provides feedback to refine the initial prompts. Human evaluations and perplexity scores revealed that optimized prompts significantly enhance the model’s narrative reconstruction accuracy and confidence, demonstrating that dynamic interaction between agents substantially boosts the annotation process’s precision and efficiency. Utilizing this innovative approach, we created the “StorySense” corpus, containing 615 stories, meticulously annotated to facilitate comprehensive story analysis. The paper also demonstrates the practical application of our annotated dataset by drawing the story arcs of two distinct stories, showcasing the utility of the annotated information in story structure analysis and understanding.
2023
-
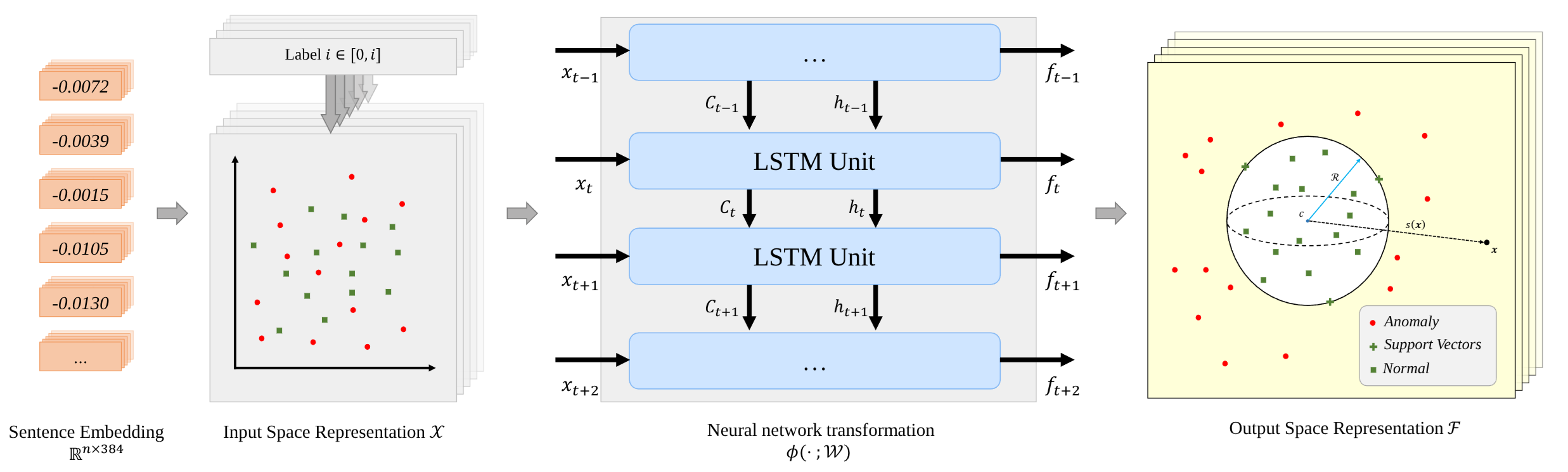 Enhancing Sentiment Analysis Results through Outlier Detection OptimizationYuetian Chen and Mei SiarXiv preprint arXiv:2311.16185, 2023
Enhancing Sentiment Analysis Results through Outlier Detection OptimizationYuetian Chen and Mei SiarXiv preprint arXiv:2311.16185, 2023When dealing with text data containing subjective labels like speaker emotions, inaccuracies or discrepancies among labelers are not uncommon. Such discrepancies can significantly affect the performance of machine learning algorithms. This study investigates the potential of identifying and addressing outliers in text data with subjective labels, aiming to enhance classification outcomes. We utilized the Deep SVDD algorithm, a one-class classification method, to detect outliers in nine text-based emotion and sentiment analysis datasets. By employing both a small-sized language model (DistilBERT base model with 66 million parameters) and non-deep learning machine learning algorithms (decision tree, KNN, Logistic Regression, and LDA) as the classifier, our findings suggest that the removal of outliers can lead to enhanced results in most cases. Additionally, as outliers in such datasets are not necessarily unlearnable, we experienced utilizing a large language model – DeBERTa v3 large with 131 million parameters, which can capture very complex patterns in data. We continued to observe performance enhancements across multiple datasets.
-
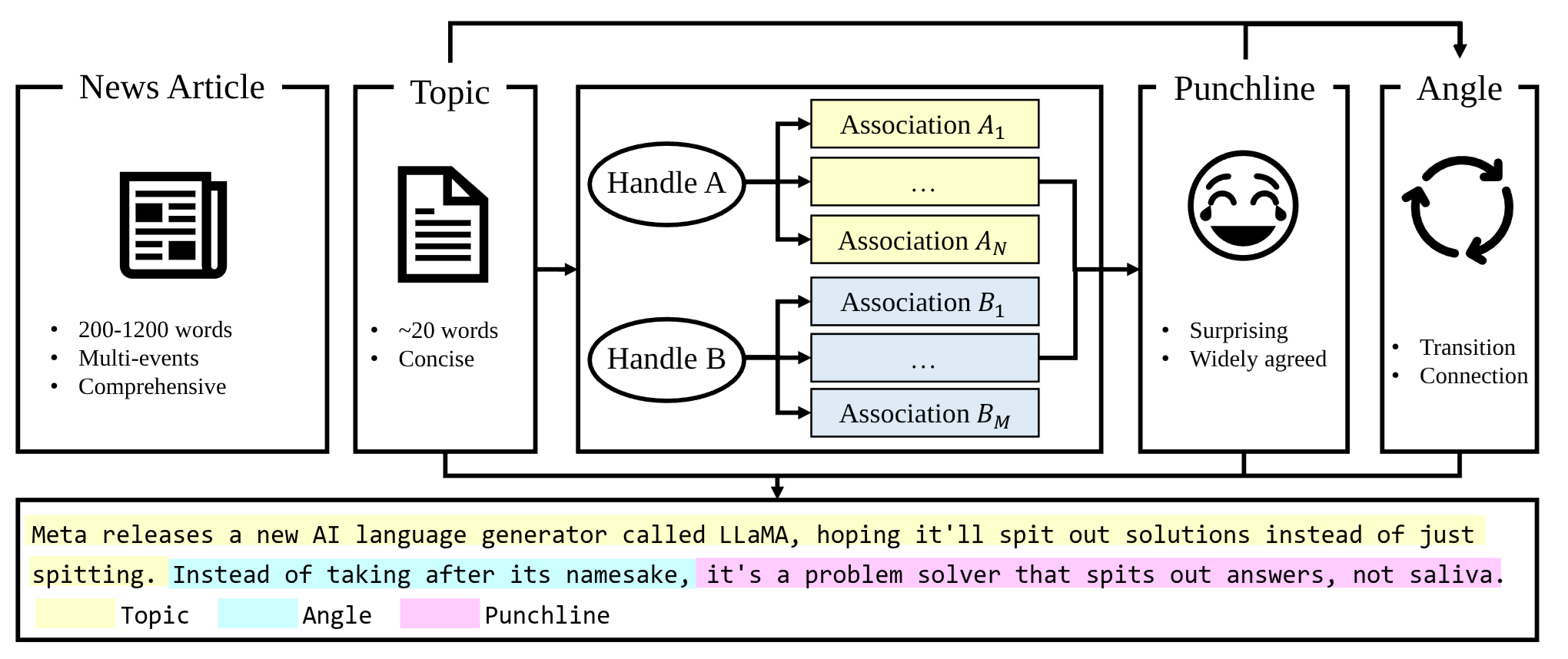 Prompt to GPT-3: Step-by-Step Thinking Instructions for Humor GenerationYuetian Chen, Bowen Shi, and Mei Si14th International Conference on Computational Creativity, 2023
Prompt to GPT-3: Step-by-Step Thinking Instructions for Humor GenerationYuetian Chen, Bowen Shi, and Mei Si14th International Conference on Computational Creativity, 2023Artificial intelligence has made significant progress in natural language processing, with models like GPT-3 demonstrating impressive capabilities. However, these models still have limitations when it comes to complex tasks that require an understanding of the user, such as mastering human comedy writing strategies. This paper explores humor generation using GPT-3 by modeling human comedy writing theory and leveraging step-by-step thinking instructions. In addition, we explore the role of cognitive distance in creating humor.
-
 Automated Visual Story Synthesis with Character Trait ControlYuetian Chen, Bowen Shi, Peiru Liu, and 2 more authorsArtificial Intelligence and Social Computing, 2023
Automated Visual Story Synthesis with Character Trait ControlYuetian Chen, Bowen Shi, Peiru Liu, and 2 more authorsArtificial Intelligence and Social Computing, 2023Visual storytelling is an art form that has been utilized for centuries to communicate stories, convey messages, and evoke emotions. The images and text must be used in harmony to create a compelling narrative experience. With the rise of text-to-image generation models such as Stable Diffusion, it is becoming more promising to investigate methods of automatically creating illustrations for stories. However, these diffusion models are usually developed to generate a single image, resulting in a lack of consistency be- tween figures and objects across different illustrations of the same story, which is especially important in stories with human characters.This work introduces a novel technique for creating consistent human figures in visual stories. This is achieved in two steps. The first step is to collect human portraits with various identifying characteristics, such as gender and age, that describe the character. The second step is to use this collection to train DreamBooth to generate a unique token ID for each type of character. These IDs can then be used to replace the names of the story characters in the image-generation process. By combining these two steps, we can create controlled human figures for various visual storytelling contexts.
-
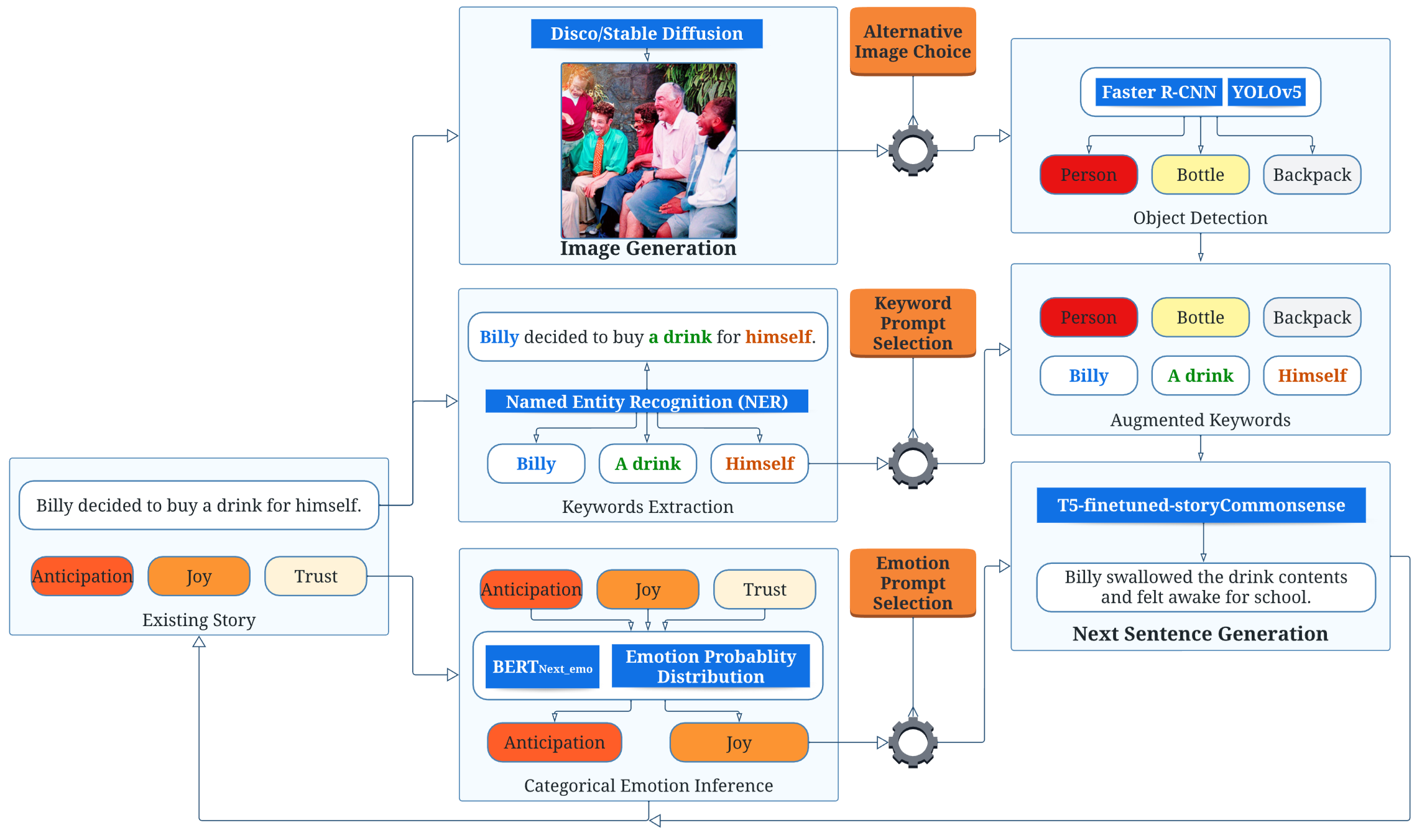 Visual Story Generation Based on Emotion and KeywordsYuetian Chen, Ruohua Li, Bowen Shi, and 2 more authors18th AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, 2023
Visual Story Generation Based on Emotion and KeywordsYuetian Chen, Ruohua Li, Bowen Shi, and 2 more authors18th AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, 2023Automated visual story generation aims to produce stories with corresponding illustrations that exhibit coherence, progression, and adherence to characters’ emotional development. This work proposes a story generation pipeline to co-create visual stories with the users. The pipeline allows the user to control events and emotions on the generated content. The pipeline includes two parts: narrative and image generation. For narrative generation, the system generates the next sentence using user-specified keywords and emotion labels. For image generation, diffusion models are used to create a visually appealing image corresponding to each generated sentence. Further, object recognition is applied to the generated images to allow objects in these images to be mentioned in future story development.
2021
- Automated Cell Recognition using Single-cell RNA Sequencing with Machine LearningChengqi Xu, Yuetian Chen, and Yiyang CaoIn 2021 5th International Conference on Computational Biology and Bioinformatics, 2021
- A review of self-encoding language models for bidirectional representationYuetian ChenIn SPIE Vol, 2021